My entire professional career I've been a note-taker at work. In the beginning, I used the Journal template of Lotus notes.

Image borrowed from the University of Windsor IT department
I used the journal extensively throughout my internship with IBM. Each day got a new entry, and each day's entry was filled with goals, notes on what I was learning, and debugging notes about what I was working on. Everything went in the journal, even PDFs of papers I was reading, along with the notes about them. Using its full text search, the Notes journal was how I survived my internship, and the huge volume of information that I had to deal with there.
Strangely, the single-fulltext-DB practice didn't come back to school with me, and I returned to paper notes in classes; perhaps for the better. In work though, it's hard to write down a stack trace, and find it again later, so when i went back to IBM as a full time employee, I wanted to have another database of notes. For all the power of the Lotus Notes DB, it had some downsides that I didn't like, and so I didn't want to return to that, so I went hunting for a solution.
I landed on Zim Wiki. It served me quite well through my term, though in the last few months I worked there I got a MacBook, and I discovered that while Zim is functional, it isn't excellent (I used the instructions here along with an Automator app to launch it).
I've tried to make sure every intern I worked with found their own solution to taking notes. Some took up Zim, but the last intern I worked with at IBM also had a Mac, and he introduced me to an interesting app called Quiver (Thanks Ray!), that I've been using for the last few months.

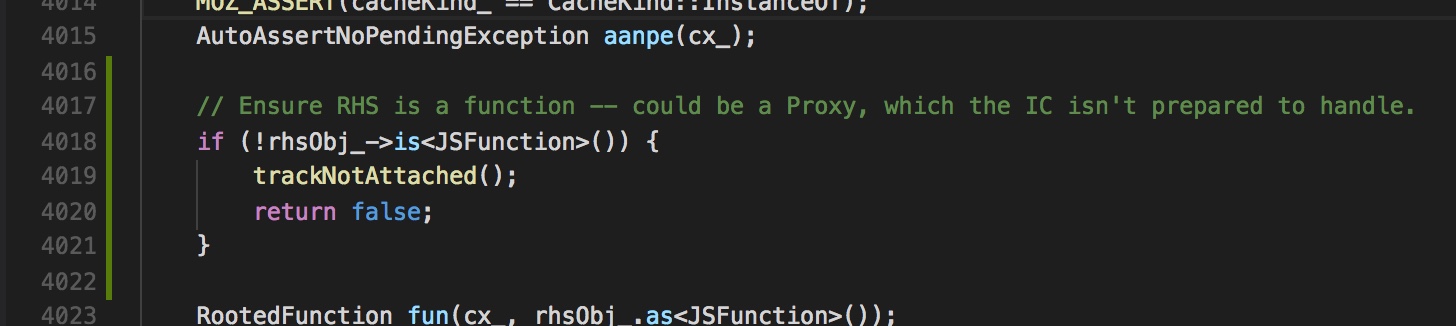
Quiver in action. In this view, the Markdown sources are being rendered previewed in the split pane view.
Quiver's most unique feature is the notion of cells. Each document in a Quiver notebook consists of one or more 'cells' in order. A cell has a type, corresponding to its content: Text, Code, Markdown, Latex or Diagram. The code cells are powered by the Ace editor component, and have syntax highlighting built in.
You can add cells, split cells and re-order them, using keystrokes to change between types.
Documents can be tagged for organization, and the full-text search seems pretty good so far.
So far, my experience with Quiver has been quite positive. Every day one of the first things I do is create a new note in my "Work Logs" notebook, titled by the date, and in it I write down my days goals as a checklist, as I understand them in the morning. In that note I keep casual debugging notes, hypotheses I need to explore etc. I also have a note for many bugs I work on, where I collate more of the information in a larger chunk, if warranted.
One of the magical things (to me at least, coming from Zim) is that rich text paste works very well; this is great for capturing IRC-logs formatted by my IRC client, or syntax highlighted code from here or there. I can also capture images by pasting them in (though, this also worked OK in Zim).
There are some concerns I have with Quiver though, that make me give it at best a qualified recommendation.
- As near a I can tell, it's developed by a single developer, and I don't think he makes enough on it to work on it full time. While the application has been solid as a rock to me, it's clear there's still lots of places where work could be done. For example, there's no touch-bar support (to be honest, I just want to use the emoji picker, though it would be neat to see the cell type accessible from the touch-bar).
- There are also a few little bugs I've encountered, almost all related to rich text editing. For example, the checkboxes are a bit finicky to edit around (and don't behave like bullets as I expected).
Overall, I am really enjoying Quiver, and will definitely keep using it